Anaconda
- Anaconda部分原博客
- Anaconda(官方网站)就是可以便捷获取包且对包能够进行管理,同时对环境可以统一管理的发行版本。
- Anaconda包含了conda、Python在内的超过180个科学包及其依赖项。
- 其特点的实现是因为包含:
- conda包
- 环境管理器
- 1000+开源库
特点:
- 开源
- 安装过程简单
- 高性能使用python和R语言
- 免费的社区支持
区别
1. Anaconda
- Anaconda是一个包含180+的科学包及其依赖项的发行版本。
- 其包含的科学包包括:
- conda, numpy, scipy, ipython notebook等。
2. conda
conda是包及其依赖项和环境的管理工具。
适用语言:
- Python, R, Ruby, Lua, Scala, Java, JavaScript, C/C++, FORTRAN。
适用平台:
- Windows, macOS, Linux
用途:
- 快速安装、运行和升级包及其依赖项。
- 在计算机中便捷地创建、保存、加载和切换环境。
如果你需要的包要求不同版本的Python,你无需切换到不同的环境,因为conda同样是一个环境管理器。仅需要几条命令,你可以创建一个完全独立的环境来运行不同的Python版本,同时继续在你常规的环境中使用你常用的Python版本。——conda官方网站
- onda为Python项目而创造,但可适用于上述的多种语言。
- conda包和环境管理器包含于Anaconda的所有版本当中。
3. pip
pip是用于安装和管理软件包的包管理器。
pip编写语言:Python。
Python中默认安装的版本:
- Python 2.7.9及后续版本:默认安装,命令为
pip - Python 3.4及后续版本:默认安装,命令为
pip3
- Python 2.7.9及后续版本:默认安装,命令为
pip名称的由来:pip采用的是递归缩写进行命名的。其名字被普遍认为来源于2处:
- “Pip installs Packages”(“pip安装包”)
- “Pip installs Python”(“pip安装Python”)
4.virtualenv
virtualenv:用于创建一个独立的Python环境的工具。
解决问题:
- 当一个程序需要使用Python 2.7版本,而另一个程序需要使用Python 3.6版本,如何同时使用这两个程序?
- 如果将所有程序都安装在系统下的默认路径,如:
/usr/lib/python2.7/site-packages,当不小心升级了本不该升级的程序时,将会对其他的程序造成影响。 - 如果想要安装程序并在程序运行时对其库或库的版本进行修改,都会导致程序的中断。
- 在共享主机时,无法在全局
site-packages目录中安装包。
virtualenv将会为它自己的安装目录创建一个环境,这并不与其他virtualenv环境共享库;同时也可以选择性地不连接已安装的全局库。
pip与conda比较:
依赖项检查
- pip:
- 不一定会展示所需其他依赖包。
- 安装包时或许会直接忽略依赖项而安装,仅在结果中提示错误。
- conda:
- 列出所需其他依赖包。
- 安装包时自动安装其依赖项。
- 可以便捷地在包的不同版本中自由切换。
- pip:
环境管理
- pip:维护多个环境难度较大。
- conda:比较方便地在不同环境之间进行切换,环境管理较为简单。
对系统自带Python的影响
- pip:在系统自带Python中包的**更新/回退版本/卸载将影响其他程序。
- conda:不会影响系统自带Python。
适用语言
- pip:仅适用于Python。
- conda:适用于Python, R, Ruby, Lua, Scala, Java, JavaScript, C/C++, FORTRAN。
conda与pip、virtualenv的关系
- conda结合了pip和virtualenv的功能。
安装
查看是否安装了python和anaconda:

$ conda list:如果Anaconda被成功安装,则会显示已经安装的包名和版本号。$ python:进入python终端的命令行- 如果同时安装了Anaconda,则会显示上图红色的部分
- exit() / quit():退出
终端输入
$ anaconda-navigator将会打开anaconda-navigator图形界面
安装教程:自行百度,或者原博客有
操作
管理conda和环境
- 验证conda已被安装
1 | conda list # 显示已经安装的包名和版本号 |
创建新环境
1 | conda create --name <env_name> <package_names> |
<env_name>:即创建的环境名。建议以英文命名,且不加空格,名称两边不加尖括号“<>”。<package_names>:即安装在环境中的包名。名称两边不加尖括号“<>”。- 如果要安装指定的版本号,则只需要在包名后面以
=和版本号的形式执行。如:conda create --name python2 python=2.7,即创建一个名为“python2”的环境,环境中安装版本为2.7的python。 - 如果要在新创建的环境中创建多个包,则直接在
<package_names>后以空格隔开,添加多个包名即可。如:conda create -n python3 python=3.5 numpy pandas,即创建一个名为“python3”的环境,环境中安装版本为3.5的python,同时也安装了numpy和pandas。
- 如果要安装指定的版本号,则只需要在包名后面以
- 默认情况下,新创建的环境将会被保存在
/Users/<user_name>/anaconda3/env目录下,其中,<user_name>为当前用户的用户名。
切换环境
1 | Linux 或macOS |
如果创建环境后安装Python时没有指定Python的版本,那么将会安装与Anaconda版本相同的Python版本,即如果安装Anaconda第2版,则会自动安装Python 2.x;如果安装Anaconda第3版,则会自动安装Python 3.x。
当成功切换环境之后,在该行行首将以“(env_name)”或“[env_name]”开头。其中,“env_name”为切换到的环境名。如:在macOS系统中执行
source active python2,即切换至名为“python2”的环境,则行首将会以(python2)开头。
退出环境至root
1 | Linux 或macOS |
- 当执行退出当前环境,回到root环境命令后,原本行首以 “(env_name)” 或 “[env_name]” 开头的字符将不再显示。
显示已创建的环境
1 | conda info -envs |

- 结果中星号
*所在行即为当前所在环境。macOS系统中默认创建的环境名为base。
复制环境
1 | conda create --name <new_env_name> --clone <copied_env_name> |
<copied_env_name>即为被复制/克隆环境名。环境名两边不加尖括号“<>”<new_env_name>即为复制之后新环境的名称。环境名两边不加尖括号“<>”。- 如:
$ conda create --name py2 --clone python2,即为克隆名为“python2”的环境,克隆后的新环境名为“py2”。此时,环境中将同时存在“python2”和“py2”环境,且两个环境的配置相同。
- 如:
删除环境
1 | conda remove --name <env_name> --all |
复制环境
1 | conda create --name <new_env_name> --clone <copied_env_name> |
管理包
1. 查找可供安装的包版本
- 精确查找
1 | $ conda search --full-name <package_full_name> |
--full-name:精确查找的参数。<package_full_name>:是被查找包的全名。包名两边不加尖括号“<>”。- 例如:
conda search --full-name python即查找全名为“python”的包有哪些版本可供安装。
- 例如:
- 模糊查找
1 | conda search <text> |
<text>:查找含有此字段的包名。此字段两边不加尖括号“<>”。- 例如:
conda search py即查找含有“py”字段的包,有哪些版本可供安装。
- 例如:
2. 获取当前环境中已安装的包信息
1 | conda list |
- 执行上述命令后将在终端显示当前环境已安装包的包名及其版本号。
3. 安装包
- 在指定环境中安装包
1 | conda install --name <env_name> <package_name> |
<env_name>:将包安装的指定环境名。环境名两边不加尖括号“<>”。<package_name>:要安装的包名。包名两边不加尖括号“<>”。- 例如:
conda install --name python2 pandas即在名为“python2”的环境中安装pandas包。
- 例如:
- 在当前环境中安装包
1 | conda install <package_name> |
<package_name>:要安装的包名。包名两边不加尖括号“<>”。- 执行命令后在当前环境中安装包。
- 例如:
conda install pandas即在当前环境中安装pandas包。
- 例如:
- 使用pip安装包
使用场景:
- 当使用
conda install无法进行安装时,可以使用pip进行安装。例如:see包。
1 | pip install <package_name> |
<pacage_name>:指定安装包的名称。包名两边不加尖括号“<>”。- 如:
pip install see即安装see包。
- 如:
注意:
- pip只是包管理器,无法对环境进行管理。因此如果想在指定环境中使用pip进行安装包,则需要先切换到指定环境中,再使用pip命令安装包。
- pip无法更新python,因为pip并不将python视为包。
- pip可以安装一些conda无法安装的包;conda也可以安装一些pip无法安装的包。因此当使用一种命令无法安装包时,可以尝试用另一种命令。
- 从Anaconda.org安装包
使用场景
- 当使用
conda install无法进行安装时,可以考虑从Anaconda.org中获取安装包的命令,并进行安装。
注意
- 从Anaconda.org安装包时,无需注册。
- 在当前环境中安装来自于Anaconda.org的包时,需要通过输入要安装的包在Anaconda.org中的路径作为获取途径(channel)
4. 卸载包
- 卸载指定环境中的包
1 | conda remove --name <env_name> <package_name> |
<env_name>:卸载包所在指定环境的名称。环境名两边不加尖括号“<>”<package_name>:要卸载包的名称。包名两边不加尖括号“<>”。- 例如:
conda remove --name python2 pandas即卸载名为“python2”中的pandas包。
- 例如:
- 卸载当前环境中的包
1 | conda remove <package_name> |
<package_name>:要卸载包的名称。包名两边不加尖括号“<>”。- 执行命令后即在当前环境中卸载指定包。
- 例如:
conda remove pandas即在当前环境中卸载pandas包。
- 例如:
5. 更新包
- 更新所有包
1 | conda update --all |
- 建议:在安装Anaconda之后执行上述命令更新Anaconda中的所有包至最新版本,便于使用。
- 更新指定包
1 | conda update <package_name> |
- 注意:
<package_name>为指定更新的包名。包名两边不加尖括号“<>”。- 更新多个指定包,则包名以空格隔开,向后排列。如:
conda update pandas numpy matplotlib即更新pandas、numpy、matplotlib包。
Python
简介
- Python 是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言
- Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有比其他语言更有特色语法结构。
- Python 是一种解释型语言:这意味着开发过程中没有了编译这个环节。类似于PHP和Perl语言。
- Python 是交互式语言:这意味着,您可以在一个 Python 提示符 >>> 后直接执行代码。
- Python 是面向对象语言: 这意味着Python支持面向对象的风格或代码封装在对象的编程技术。
- Python 是初学者的语言:Python 对初级程序员而言,是一种伟大的语言,它支持广泛的应用程序开发,从简单的文字处理到 WWW 浏览器再到游戏。
特点:
- 易于学习:Python有相对较少的关键字,结构简单,和一个明确定义的语法,学习起来更加简单。
- 易于阅读:Python代码定义的更清晰。
- 易于维护:Python的成功在于它的源代码是相当容易维护的。
- 一个广泛的标准库:Python的最大的优势之一是丰富的库,跨平台的,在UNIX,Windows和Macintosh兼容很好。
- 互动模式:互动模式的支持,您可以从终端输入执行代码并获得结果的语言,互动的测试和调试代码片断。
- 可移植:基于其开放源代码的特性,Python已经被移植(也就是使其工作)到许多平台。
- 可扩展:如果你需要一段运行很快的关键代码,或者是想要编写一些不愿开放的算法,你可以使用C或C++完成那部分程序,然后从你的Python程序中调用。
- 数据库:Python提供所有主要的商业数据库的接口。
- GUI编程:Python支持GUI可以创建和移植到许多系统调用。
- 可嵌入:你可以将Python嵌入到C/C++程序,让你的程序的用户获得”脚本化”的能力。
安装
安装过程:自行百度云
环境变量
| PYTHONPATH | PYTHONPATH是Python搜索路径,默认我们import的模块都会从PYTHONPATH里面寻找。 |
|---|---|
| PYTHONSTARTUP | Python启动后,先寻找PYTHONSTARTUP环境变量,然后执行此变量指定的文件中的代码。 |
| PYTHONCASEOK | 加入PYTHONCASEOK的环境变量, 就会使python导入模块的时候不区分大小写. |
| PYTHONHOME | 另一种模块搜索路径。它通常内嵌于的PYTHONSTARTUP或PYTHONPATH目录中,使得两个模块库更容易切换。 |
集成开发环境(IDE, Integrated Development Environment):PyCharm
- PyCharm 是由 JetBrains 打造的一款 Python IDE,支持 macOS、 Windows、 Linux 系统。
- 功能 :
- 调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控制……
- 下载地址
- 安装地址
基础教程
中文编码
- python3.x源文件默认支持中文编码,无需制定
- 如果你使用编辑器,同时需要设置 py 文件存储的格式为 UTF-8,否则会出现错误信息
- 进入 file > Settings,在输入框搜索 encoding。
- 找到 Editor > File encodings,将 IDE Encoding 和 Project Encoding 设置为utf-8。
输入输出
1 | print num # python2.x |
- 默认换行输出,如果不需要换行,在末尾加入逗号
print x,这样的话只会空格
1 | for x in [1, 2, 3]: print (x, end="。") # 1。2。3。 |
- 指定以”。”为末尾输出,默认是”\n”换行
等待用户输入:
1 | #!/usr/bin/python |
两种输出值的方式:
- 表达式
- print()
- 文件使用文件对象write()方法,标准输出文件可以用 sys.stdout 引用。
- 如果你希望输出的形式更加多样,可以使用 str.format() 函数来格式化输出值。
- 如果你希望将输出的值转成字符串,可以使用 repr() 或 str() 函数来实现。
- str(): 函数返回一个用户易读的表达形式。
- repr(): 产生一个解释器易读的表达形式。
python2.x中使用python2.x的print函数:
from __future__ import print_function- 可以导入
__future__包,该包禁用 Python2.x 的 print 语句,采用 Python3.x 的 print 函数 - Python3.x 与 Python2.x 的许多兼容性设计的功能可以通过
__future__这个包来导入
输出格式
1 | print("{0:<10}{1:<10}{2:>5}".format('word', 'len', 'num')) |
- 以标准格式输出
标识符
标识符由字母、数字、下划线组成。
所有标识符可以包括英文、数字以及下划线(_),但不能以数字开头。
Python 中的标识符是区分大小写的。
以下划线开头的标识符是有特殊意义的。
- 以单下划线开头
_foo的代表不能直接访问的类属性,需通过类提供的接口进行访问,不能用from xxx import *而导入。 - 以双下划线开头的
__foo代表类的私有成员,以双下划线开头和结尾的__foo__代表 Python 里特殊方法专用的标识- 如
__init__()代表类的构造函数。
- 如
- 以单下划线开头
Python 可以同一行显示多条语句,方法是用分号 ; 分开
print ('hello'); print ('world')
保留字符
- 不能用作常数或变数,或任何其他标识符名称
- 所有 Python 的关键字只包含小写字母
| and | exec | not |
|---|---|---|
| assert | finally | or |
| break | for | pass |
| class | from | |
| continue | global | raise |
| def | if | return |
| del | import | try |
| elif | in | while |
| else | is | with |
| except | lambda | yield |
行和缩进
- 学习 Python 与其他语言最大的区别就是,Python 的代码块不使用大括号 {} 来控制类,函数以及其他逻辑判断。python 最具特色的就是用缩进来写模块。
- 缩进的空白数量是可变的,但是所有代码块语句必须包含相同的缩进空白数量,这个必须严格执行。
多行语句:
1 | total = item_one + \ |
引号:
1 | word = 'word' |
- 三引号可以由多行组成,编写多行文本的快捷语法,常用于文档字符串,在文件的特定地点,被当做注释。
空行:
- 函数之间或类的方法之间用空行分隔,表示一段新的代码的开始。类和函数入口之间也用一行空行分隔,以突出函数入口的开始。
- 空行与代码缩进不同,空行并不是Python语法的一部分。书写时不插入空行,Python解释器运行也不会出错。但是空行的作用在于分隔两段不同功能或含义的代码,便于日后代码的维护或重构。
- 记住:空行也是程序代码的一部分。
变量类型
变量赋值
1 | a = b = c = 1 |
- 以上实例,创建一个整型对象,值为1,三个变量被分配到相同的内存空间上。
1 | a, b, c = 1, 2, "john" |
- 为多个对象指定多个变量
运算符
算术运算符
- a = 10,b = 21
运算符 描述 实例 + 加 - 两个对象相加 a + b 输出结果 31 - 减 - 得到负数或是一个数减去另一个数 a - b 输出结果 -11 * 乘 - 两个数相乘或是返回一个被重复若干次的字符串 a * b 输出结果 210 / 除 - x 除以 y b / a 输出结果 2.1 % 取模 - 返回除法的余数 b % a 输出结果 1 ** 幂 - 返回x的y次幂 a**b 为10的21次方 // 取整除 - 向下取接近商的整数 >>> 9//2 4 >>> -9//2 -5比较(关系)运算符
- a = 10,b = 20
运算符 描述 实例 == 等于 - 比较对象是否相等 (a == b) 返回 False。 != 不等于 - 比较两个对象是否不相等 (a != b) 返回 True。 > 大于 - 返回x是否大于y (a > b) 返回 False。 < 小于 - 返回x是否小于y。所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量True和False等价。注意,这些变量名的大写。 (a < b) 返回 True。 >= 大于等于 - 返回x是否大于等于y。 (a >= b) 返回 False。 <= 小于等于 - 返回x是否小于等于y。 (a <= b) 返回 True。 赋值运算符
- a = 10,b = 20
运算符 描述 实例 = 简单的赋值运算符 c = a + b 将 a + b 的运算结果赋值为 c += 加法赋值运算符 c += a 等效于 c = c + a -= 减法赋值运算符 c -= a 等效于 c = c - a *= 乘法赋值运算符 c *= a 等效于 c = c * a /= 除法赋值运算符 c /= a 等效于 c = c / a %= 取模赋值运算符 c %= a 等效于 c = c % a **= 幂赋值运算符 c **= a 等效于 c = c ** a //= 取整除赋值运算符 c //= a 等效于 c = c // a := 海象运算符,可在表达式内部为变量赋值。Python3.8 版本新增运算符。 在这个示例中,赋值表达式可以避免调用 len() 两次: if (n := len(a)) > 10: print(f"List is too long ({n} elements, expected <= 10)")逻辑运算符
- a = 10,b = 20
运算符 逻辑表达式 描述 实例 and x and y 布尔”与” - 如果 x 为 False,x and y 返回 x 的值,否则返回 y 的计算值。 (a and b) 返回 20。 or x or y 布尔”或” - 如果 x 是 True,它返回 x 的值,否则它返回 y 的计算值。 (a or b) 返回 10。 not not x 布尔”非” - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 not(a and b) 返回 False 位运算符
1
2
3
4
5
6
7
8
9a = 60 # 0011 1100
b = 13 # 0000 1101
-----------------
a&b = 12 # 0000 1100 按位与
a|b = 61 # 0011 1101 按位或
a^b = 49 # 0011 0001 按位异或
~a = -61 # 1100 0011 按位取反
a<<2 = 240 # 1111 0000 左移
a>>2 = 15 # 0000 1111 右移成员运算符
运算符 描述 实例 in 如果在指定的序列中找到值返回 True,否则返回 False。 x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 not in 如果在指定的序列中没有找到值返回 True,否则返回 False。 x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 身份运算符
- 比较两个对象的存储单元
id():获取对象内存地址。- is和==
- is 用于判断两个变量引用对象是否为同一个
- == 用于判断引用变量的值是否相等。
运算符 描述 实例 is is 是判断两个标识符是不是引用自一个对象 x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False is not is not 是判断两个标识符是不是引用自不同对象 x is not y , 类似 **id(a) != id(b)**。如果引用的不是同一个对象则返回结果 True,否则返回 False。 运算符优先级
标准数据类型
- 不可变数据:Number(数字)、String(字符串)、Tuple(元组);
- 变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变 a 的值,相当于新生成了 a。
- 可变数据:List(列表)、Dictionary(字典)、Set(集合)。
- 变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了。
Numbers(数字)
数字数据类型用于存储数值。
他们是不可改变的数据类型,这意味着改变数字数据类型会分配一个新的对象。
当你指定一个值时,Number 对象就会被创建:
1 | var1 = 1 |
删除
1 | del var1[,var2,[var3[..., varN]]] |
数字类型:
- 查询变量所指的对象类型
- 内置的
type()函数:不会认为子类是一种父类类型 isinstance():会认为子类是一种父类类型
- 内置的
| int | long | float | complex |
|---|---|---|---|
| 10 | 51924361L | 0.0 | 3.14j |
| 100 | -0x19323L | 15.20 | 45.j |
| -786 | 0122L | -21.9 | 9.322e-36j |
| 080 | 0xDEFABCECBDAECBFBAEl | 32.3e+18 | .876j |
| -0490 | 535633629843L | -90. | -.6545+0J |
| -0x260 | -052318172735L | -32.54e100 | 3e+26J |
| 0x69 | -4721885298529L | 70.2E-12 | 4.53e-7j |
int(有符号整型):通常被称为是整型或整数,是正或负整数,不带小数点
long(长整数)
长整型也可以使用小写 l,但是还是建议您使用大写 L,避免与数字 1 混淆。Python使用 L 来显示长整型。
long 类型只存在于 Python2.X 版本中,在 2.2 以后的版本中,int 类型数据溢出后会自动转为long类型。在 Python3.X 版本中 long 类型被移除,使用 int 替代。
float(浮点数): 浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 102 = 250)
bool(布尔值)
python2中没有这个数据类型
complex(复数)
- 复数由实数部分和虚数部分构成,可以用 a + bj,或者 complex(a,b) 表示
- 复数的实部 a 和虚部 b 都是浮点型。
运算:
1 | 2 / 4 # 除法,得到一个浮点数 |
String(字符串)
1 | s = "hello world" |
下标索引
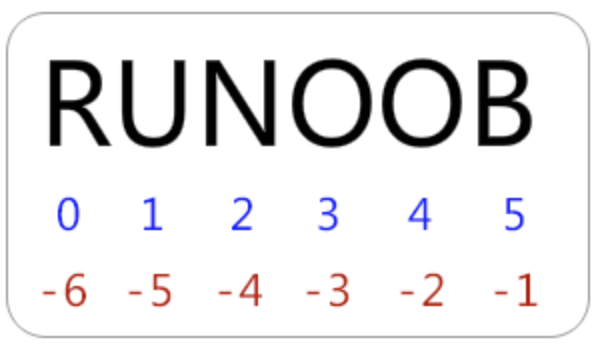
- 左往右:0开始,右往左:-1开始
在Python2中,普通字符串是以8位ASCII码进行存储的,而Unicode字符串则存储为16位unicode字符串,这样能够表示更多的字符集。使用的语法是在字符串前面加上前缀 u。
在Python3中,所有的字符串都是Unicode字符串
字符串操作
1 | s = 'abcdef' |
- 使用
[头下标:尾下标:步长]来截取字符串,在头下标-尾下标的范围内以步长来截取字符 - 注意:所有的截取都取不到尾下标
原始字符串:
1 | print(r'\n') # \n,不会进行换行,而是直接输出 |
- 所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。
- 原始字符串除在字符串的第一个引号前加上字母 r/R以外,与普通字符串有着几乎完全相同的语法。
字符串格式化:
1 | print ("我叫 %s 今年 %d 岁!" % ('小明', 10)) |
使用与 C 中 sprintf 函数一样的语法。
Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。
f-string:
- 之后版本添加的,称之为字面量格式化字符串,是新的格式化字符串的语法。
- 不用再去判断使用 %s,还是 %d。
1 | #### 以前 ### |
内建函数:
列表 = 字符串.split(“str”)
capitalize()
- 将字符串的第一个字符转换为大写
center(width, fillchar)
- 返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。
count(str, beg= 0,end=len(string))
- 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数
bytes.decode(encoding=”utf-8”, errors=”strict”)
Python3 中没有 decode 方法,但我们可以使用 bytes 对象的 decode() 方法来解码给定的 bytes 对象,这个 bytes 对象可以由 str.encode() 来编码返回。
encode(encoding=’UTF-8’,errors=’strict’)
- 以 encoding 指定的编码格式编码字符串,如果出错默认报一个ValueError 的异常,除非 errors 指定的是’ignore’或者’replace’
endswith(suffix, beg=0, end=len(string))
- 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False.
expandtabs(tabsize=8)
- 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8 。
8
- 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8 。
find(str, beg=0, end=len(string))
- 检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1
index(str, beg=0, end=len(string))
- 跟find()方法一样,只不过如果str不在字符串中会报一个异常。
isalnum()
- 如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False
isalpha()
- 如果字符串至少有一个字符并且所有字符都是字母或中文字则返回 True, 否则返回 False
isdigit()
- 如果字符串只包含数字则返回 True 否则返回 False..
islower()
- 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False
isnumeric()
- 如果字符串中只包含数字字符,则返回 True,否则返回 False
isspace()
- 如果字符串中只包含空白,则返回 True,否则返回 False.
istitle()
- 如果字符串是标题化的(见 title())则返回 True,否则返回 False
isupper()
- 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False
‘char’.join(seq)
- 以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串
len(string)
- 返回字符串长度
ljust(width[, fillchar])
- 返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。
lower()
- 转换字符串中所有大写字符为小写.
lstrip()
- 截掉字符串左边的空格或指定字符。
maketrans()
- 创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目
max(str)
- 返回字符串 str 中最大的字母。
min(str)
- 返回字符串 str 中最小的字母。
replace(old, new [, max])
- 把将字符串中的 old 替换成 new,如果 max 指定,则替换不超过 max 次。
注意:replace函数将会返回一个新的字符串,原来的字符串不会改变
需要使用:
str = str.replace(old, new)rfind(str, beg=0,end=len(string))
- 类似于 find()函数,不过是从右边开始查找.
rindex( str, beg=0, end=len(string))
- 类似于 index(),不过是从右边开始.
rjust(width,[, fillchar])
- 返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串
rstrip()
- 删除字符串字符串末尾的空格.
split(str=””, num=string.count(str))
- 以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num+1 个子字符串
splitlines([keepends])
- 按照行(‘\r’, ‘\r\n’, \n’)分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。
startswith(substr, beg=0,end=len(string))
- 检查字符串是否是以指定子字符串 substr 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查。
strip([chars])
- 在字符串上执行 lstrip()和 rstrip()
swapcase()
- 将字符串中大写转换为小写,小写转换为大写
title()
- 返回”标题化”的字符串,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle())
translate(table, deletechars=””)
- 根据 str 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 deletechars 参数中
upper()
- 转换字符串中的小写字母为大写
zfill (width)
- 返回长度为 width 的字符串,原字符串右对齐,前面填充0
isdecimal()
- 检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false。
| 序号 | 方法及描述 |
|---|---|
| 1 | capitalize() 将字符串的第一个字符转换为大写 |
| 2 | center(width, fillchar) 返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。 |
| 3 | count(str, beg= 0,end=len(string)) 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| 4 | bytes.decode(encoding=”utf-8”, errors=”strict”) Python3 中没有 decode 方法,但我们可以使用 bytes 对象的 decode() 方法来解码给定的 bytes 对象,这个 bytes 对象可以由 str.encode() 来编码返回。 |
| 5 | encode(encoding=’UTF-8’,errors=’strict’) 以 encoding 指定的编码格式编码字符串,如果出错默认报一个ValueError 的异常,除非 errors 指定的是’ignore’或者’replace’ |
| 6 | endswith(suffix, beg=0, end=len(string)) 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
| 7 | expandtabs(tabsize=8) 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8 。 |
| 8 | find(str, beg=0, end=len(string)) 检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1 |
| 9 | index(str, beg=0, end=len(string)) 跟find()方法一样,只不过如果str不在字符串中会报一个异常。 |
| 10 | isalnum() 如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False |
| 11 | isalpha() 如果字符串至少有一个字符并且所有字符都是字母或中文字则返回 True, 否则返回 False |
| 12 | isdigit() 如果字符串只包含数字则返回 True 否则返回 False.. |
| 13 | islower() 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| 14 | isnumeric() 如果字符串中只包含数字字符,则返回 True,否则返回 False |
| 15 | isspace() 如果字符串中只包含空白,则返回 True,否则返回 False. |
| 16 | istitle() 如果字符串是标题化的(见 title())则返回 True,否则返回 False |
| 17 | isupper() 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| 18 | join(seq) 以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| 19 | len(string) 返回字符串长度 |
| 20 | ljust(width[, fillchar]) 返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。 |
| 21 | lower() 转换字符串中所有大写字符为小写. |
| 22 | lstrip() 截掉字符串左边的空格或指定字符。 |
| 23 | maketrans() 创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| 24 | max(str) 返回字符串 str 中最大的字母。 |
| 25 | min(str) 返回字符串 str 中最小的字母。 |
| 26 | [replace(old, new [, max])] 把 将字符串中的 old 替换成 new,如果 max 指定,则替换不超过 max 次。 |
| 27 | rfind(str, beg=0,end=len(string)) 类似于 find()函数,不过是从右边开始查找. |
| 28 | rindex( str, beg=0, end=len(string)) 类似于 index(),不过是从右边开始. |
| 29 | rjust(width,[, fillchar]) 返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串 |
| 30 | rstrip() 删除字符串字符串末尾的空格. |
| 31 | split(str=””, num=string.count(str)) 以 str 为分隔符截取字符串,如果 num 有指定值,则仅截取 num+1 个子字符串 |
| 32 | splitlines([keepends]) 按照行(‘\r’, ‘\r\n’, \n’)分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| 33 | startswith(substr, beg=0,end=len(string)) 检查字符串是否是以指定子字符串 substr 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查。 |
| 34 | strip([chars]) 在字符串上执行 lstrip()和 rstrip() |
| 35 | swapcase() 将字符串中大写转换为小写,小写转换为大写 |
| 36 | title() 返回”标题化”的字符串,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
| 37 | translate(table, deletechars=””) 根据 str 给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到 deletechars 参数中 |
| 38 | upper() 转换字符串中的小写字母为大写 |
| 39 | zfill (width) 返回长度为 width 的字符串,原字符串右对齐,前面填充0 |
| 40 | isdecimal() 检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false。 |
List(列表)
- 通用符合数据类型,用[标识]
- 有序集合
1 | x = [0, 1, 'abc', 'def', 4 ] |
迭代
1 | a = [1, 2, 3] |
内置函数:
字符串 = ‘char’.join(列表)
len(list)
- 列表元素个数
max(list)
- 返回列表元素最大值
min(list)
- 返回列表元素最小值
list(seq\string\dict.items()…)
- 将元组、字符串、字典元素等转换为列表
list(dictionary)将会得到一个元素为元组的列表,如下:1
2
3
4
5>disList = list(dic)
># [(key0, value0), (key1, value1), (key2, value2), ...]
>disList[1] # (key1, value1)
>disList[1][0] # key1
>disList[1][1] # value1
方法
- list.append(obj)
- 在列表末尾添加新的对象
- list.count(obj)
- 统计某个元素在列表中出现的次数
- list.extend(seq)
- 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)
- list.index(obj)
- 从列表中找出某个值第一个匹配项的索引位置
- list.insert(index, obj)
- 将对象插入列表
- list.pop([index=-1])
- 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值
- list.remove(obj)
- 移除列表中某个值的第一个匹配项
- list.reverse()
- 反向列表中元素
- list.sort( key=None, reverse=False)
- 对原列表进行排序
- list.clear()
- 清空列表
- list.copy()
- 复制列表
列表元素反转
1 | def reverseWords(input): |
Tuple(元组)
元组是另一个数据类型,类似于 List(列表)。
元组用 () 标识。内部元素用逗号隔开。
与字符串一样,元组的元素不能修改,相当于只读列表。
1 | x = [1, 2] |
1 | tup1 = () # 创建空元组 |
- 元组中只包含一个元素时,需要在元素后面添加逗号,否则括号会被当作运算符使用
内置函数:
len(tuple)
- 计算元组元素个数。
max(tuple)
- 返回元组中元素最大值。
min(tuple)
- 返回元组中元素最小值。
tuple(iterable)
将可迭代系列转换为元组。
>>> list1= ['Google', 'Taobao', 'Runoob', 'Baidu'] >>> tuple1=tuple(list1) >>> tuple1 ('Google', 'Taobao', 'Runoob', 'Baidu')1
2
3
4
5
6
7
8
9
10
11
12
13
14
##### Set(集合)
* 集合(set)是由一个或数个形态各异的大小整体组成的,构成集合的事物或对象称作元素或是成员。
* 基本功能是进行成员关系测试和删除重复元素。
* 可以使用大括号 **{ }** 或者 **set()** 函数创建集合
* **注意**:创建一个空集合必须用 **set()** 而不是 **{ }**,因为 **{ }** 是用来创建一个空字典。
```python
parame = {value01,value02,...}
# 或者
parame = set(value)
集合运算
1 | a = set('abracadabra') |
基本操作:
1 | a = set('abracadabra') |
内置函数:
- len(set)
- 输出集合的个数
| 方法 | 描述 |
|---|---|
| add() | 为集合添加元素 |
| clear() | 移除集合中的所有元素 |
| copy() | 拷贝一个集合 |
| difference() | 返回多个集合的差集 |
| difference_update() | 移除集合中的元素,该元素在指定的集合也存在。 |
| discard() | 删除集合中指定的元素 |
| intersection() | 返回集合的交集 |
| intersection_update() | 返回集合的交集。 |
| isdisjoint() | 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。 |
| issubset() | 判断指定集合是否为该方法参数集合的子集。 |
| issuperset() | 判断该方法的参数集合是否为指定集合的子集 |
| pop() | 随机移除元素 |
| remove() | 移除指定元素 |
| symmetric_difference() | 返回两个集合中不重复的元素集合。 |
| symmetric_difference_update() | 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。 |
| union() | 返回两个集合的并集 |
| update() | 给集合添加元素 |
Dictionary(字典)
- 列表是有序的对象集合,字典是无序的对象集合。
- 即使排序了,放进字典也是无序的
- 两者之间的区别在于:
- 字典当中的元素是通过键来存取的,而不是通过偏移存取。
- 字典是一种映射类型,字典用 { } 标识,它是一个无序的 键(key) : 值(value) 的集合。
- 键(key)必须使用不可变类型。(列表等不行)
- 在同一个字典中,键(key)必须是唯一的,重复时选择后一个
1 | dict = {} # 创建空字典 |
内置函数
构造函数
dict():>>> dict([('aa', 1), ('bb', 2), ('cc', 3)]) {'aa': 1, 'bb': 2, 'cc': 3}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
* len(dict)
* 计算字典元素个数,即键的总数
* str(dict)
* 输出字典,以可打印的字符串表示。
* type(variable)
* 返回输入的变量类型,如果变量是字典就返回字典类型。
* keys()
* values()
| 序号 | 函数及描述 |
| :--- | :----------------------------------------------------------- |
| 1 | [radiansdict.clear()](https://www.runoob.com/python3/python3-att-dictionary-clear.html) <br />删除字典内所有元素 |
| 2 | [radiansdict.copy()](https://www.runoob.com/python3/python3-att-dictionary-copy.html) <br />返回一个字典的浅复制 |
| 3 | [radiansdict.fromkeys()](https://www.runoob.com/python3/python3-att-dictionary-fromkeys.html) <br />创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 |
| 4 | [radiansdict.get(key, default=None)](https://www.runoob.com/python3/python3-att-dictionary-get.html) <br />返回指定键的值,如果键不在字典中返回 default 设置的默认值 |
| 5 | [key in dict](https://www.runoob.com/python3/python3-att-dictionary-in.html) <br />如果键在字典dict里返回true,否则返回false |
| 6 | [radiansdict.items()](https://www.runoob.com/python3/python3-att-dictionary-items.html) <br />以列表返回可遍历的(键, 值) 元组数组 |
| 7 | [radiansdict.keys()](https://www.runoob.com/python3/python3-att-dictionary-keys.html) <br />返回一个迭代器,可以使用 list() 来转换为列表 |
| 8 | [radiansdict.setdefault(key, default=None)](https://www.runoob.com/python3/python3-att-dictionary-setdefault.html)<br /> 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | [radiansdict.update(dict2)](https://www.runoob.com/python3/python3-att-dictionary-update.html) <br />把字典dict2的键/值对更新到dict里 |
| 10 | [radiansdict.values()](https://www.runoob.com/python3/python3-att-dictionary-values.html) <br />返回一个迭代器,可以使用 list() 来转换为列表 |
| 11 | pop(key[,default\]) <br />删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| 12 | [popitem()](https://www.runoob.com/python3/python3-att-dictionary-popitem.html) <br />随机返回并删除字典中的最后一对键和值。 |
#### 数据类型转换
| 函数 | 描述 |
| :---------------------- | :-------------------------------------------------- |
| int(x) | 将x转换为一个整数 |
| float(x) | 将x转换到一个浮点数 |
| complex(real [,imag\])] | 创建一个复数,实部是real,虚部是imag |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个 (key, value)元组序列。 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
##### **进制转换:**
**二进制表示**
* 通过`0b/-0b`开头的字符串来表示二进制
```python
print 0b101 # 输出5
print 0b10 # 输出2
print -0b101 # 输出-5
bin()函数将十进制转换成而二进制表示
1 | bin(5) # 输出0b101 |
二进制位操作:
- 关于bit有一个很有用的Packag叫做bitarray,其中bitarray对象可以帮助我们存储0,1值或者Boolean值,并像list一样进行操作。
1 | from bitarray import bitarray |
1 |
逻辑
条件控制
1 | if condition_1: |
- python中没有
switch-case
循环语句
while
1 | while 判断条件(condition): |
1 | while <expr>: |
- 条件语句为 false 时执行 else 的语句块。
for
1 | for <variable> in <sequence>: |
- 在没有循环数据时执行else的语句块
range()
1 | for i in range(5): |
continue break
- 同java,c++等的使用一样
pass
- pass是空语句,是为了保持程序结构的完整性。
- pass 不做任何事情,一般用做占位语句
遍历
- 在字典中遍历时,关键字和对应的值可以使用
items()方法同时解读出来:
1 | knights = {'gallahad': 'the pure', 'robin': 'the brave'} |
- 在序列中遍历时,索引位置和对应值可以使用
enumerate()函数同时得到:
1 | for i, v in enumerate(['tic', 'tac', 'toe']): |
- 同时遍历两个或更多的序列,可以使用
zip()组合:
1 | questions = ['name', 'quest', 'favorite color'] |
- 反向遍历一个序列,首先指定这个序列,然后调用
reversed()函数:
1 | for i in reversed(range(1, 10, 2)): |
- 要按顺序遍历一个序列,使用
sorted()函数返回一个已排序的序列,并不修改原值
1 | basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana'] |
迭代器与生成器
- 迭代是Python最强大的功能之一,是访问集合元素的一种方式。
- 迭代器是一个可以记住遍历的位置的对象。
- 迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
- 迭代器有两个基本的方法:iter() 和 **next()**。
- 字符串,列表或元组对象都可用于创建迭代器:
iter()
1 | list = [1, 2, 3, 4] |
next()
1 | import sys # 引入 sys 模块 |
创建一个迭代器:
把一个类作为一个迭代器使用需要在类中实现两个方法 __iter__() 与__next__() 。
如果你已经了解的面向对象编程,就知道类都有一个构造函数,Python 的构造函数为 init(), 它会在对象初始化的时候执行。
- 更多内容查阅:Python3 面向对象
__iter__():返回一个特殊的迭代器对象, 这个迭代器对象实现了 __next__() 方法并通过 StopIteration 异常标识迭代的完成。
__next__():(Python 2 里是 next())会返回下一个迭代器对象。
创建一个返回数字的迭代器,初始值为 1,逐步递增 1:
1 | class MyNumbers: |
StopIteration
- StopIteration 异常用于标识迭代的完成,防止出现无限循环的情况,在__next__() 方法中我们可以设置在完成指定循环次数后触发 StopIteration 异常来结束迭代。
1 | class MyNumbers: |
生成器
- 在 Python 中,使用了 yield 的函数被称为生成器(generator)。
- 跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
- 在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
- 调用一个生成器函数,返回的是一个迭代器对象。
1 | # 使用 yield 实现斐波那契数列 |
函数
1 | def 函数名(参数列表): |
参数传递
python 中一切都是对象,严格意义我们不能说值传递还是引用传递,我们应该说传不可变对象和传可变对象。
- 不可变类型:类似 C++ 的值传递,如 整数、字符串、元组。如 fun(a),传递的只是 a 的值,没有影响 a 对象本身。如果在 fun(a))内部修改 a 的值,则是新生成来一个 a。
- 可变类型:类似 C++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后 fun 外部的 la 也会受影响
调用函数时可使用的正式参数类型:
必需参数
必需参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样。
1
2
3
4
5
6
7
8#可写函数说明
def printme( str ):
"打印任何传入的字符串"
print (str)
return
# 调用 printme 函数,不加参数会报错
printme()
关键字参数
关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值。
使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
1
2
3
4
5
6
7
8
9#可写函数说明
def printinfo( name, age ):
"打印任何传入的字符串"
print ("名字: ", name)
print ("年龄: ", age)
return
#调用printinfo函数
printinfo( age=50, name="runoob" )
默认参数
调用函数时,如果没有传递参数,则会使用默认参数。以下实例中如果没有传入 age 参数,则使用默认值:
1
2
3
4
5
6
7
8
9
10#可写函数说明
def printinfo( name, age = 35 ):
"打印任何传入的字符串"
print ("名字: ", name)
print ("年龄: ", age)
return
#调用printinfo函数
printinfo( age=50, name="runoob" ) # 名字: runoob 年龄: 50
printinfo( name="runoob" ) # 名字: runoob 年龄: 35
不定长参数
可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述 2 种参数不同,声明时不会命名
1
2
3
4def functionname([formal_args,] *var_args_tuple ):
"函数_文档字符串"
function_suite
return [expression]带
*以元组形式传入- 如果单独出现星号
*后的参数必须用关键字传入。 def f(a,b,*,c):调用:f(1,2,c=3)
- 如果单独出现星号
带
**以字典形式传入1
2
3
4
5
6
7
8
9
10
11
12# 可写函数说明
def printinfo( arg1, *vartuple ):
"打印任何传入的参数"
print ("输出: ")
print (arg1)
print (vartuple)
# 调用printinfo 函数
printinfo( 70, 60, 50 )
# 输出
70
(60, 50)
匿名函数
- python 使用
lambda来创建匿名函数。 - 所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数。
- lambda 只是一个表达式,函数体比 def 简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
函数库
math
数学常量
pi:数学常量 pi(圆周率,一般以π来表示)e:数学常量 e,e即自然常数(自然常数)
数学函数
abs(x) 返回数字的绝对值,如abs(-10) 返回 10
ceil(x) 返回数字的上入整数,如math.ceil(4.1) 返回 5
cmp(x, y)
- 如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1。
- Python 3 已废弃,使用 (x>y)-(x<y) 替换。
exp(x) 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045
fabs(x) 返回数字的绝对值的浮点类型,如math.fabs(-10) 返回10.0
floor(x) 返回数字的下舍整数,如math.floor(4.9)返回 4
log(x) 如math.log(math.e)返回1.0,math.log(100,10)返回2.0
log10(x) 返回以10为基数的x的对数,如math.log10(100)返回 2.0
max(x1, x2,…) 返回给定参数的最大值,参数可以为序列。
min(x1, x2,…) 返回给定参数的最小值,参数可以为序列。
modf(x) 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。
pow(x, y) x**y 运算后的值。
round(x [,n]) 返回浮点数 x 的四舍五入值,如给出 n 值,则代表舍入到小数点后的位数。
- 其实准确的说是保留值将保留到离上一位更近的一端。
sqrt(x) 返回数字x的平方根。
随机数函数
- choice(seq) 从序列的元素中随机挑选一个元素
- 比如:random.choice(range(10)),从0到9中随机挑选一个整数。
- randrange ([start,] stop [,step]) 从指定范围内,按指定基数递增的集合中获取一个随机数,基数默认值为 1
- random() 随机生成下一个实数,它在[0,1)范围内。
- seed([x]) 改变随机数生成器的种子seed。如果你不了解其原理,你不必特别去设定seed,Python会帮你选择seed。
- shuffle(lst) 将序列的所有元素随机排序
- uniform(x, y) 随机生成下一个实数,它在[x,y]范围内。
三角函数
- acos(x) 返回x的反余弦弧度值。
- asin(x) 返回x的反正弦弧度值。
- atan(x) 返回x的反正切弧度值。
- atan2(y, x) 返回给定的 X 及 Y 坐标值的反正切值。
- cos(x) 返回x的弧度的余弦值。
- hypot(x, y) 返回欧几里德范数 sqrt(xx + yy)。
- sin(x) 返回的x弧度的正弦值。
- tan(x) 返回x弧度的正切值。
- degrees(x) 将弧度转换为角度,如degrees(math.pi/2) , 返回90.0
- radians(x) 将角度转换为弧度
日期和时间
很多Python函数用一个元组装起来的9组数字处理时间:
| 4位数年 | 2008 | |
|---|---|---|
| 1 | 月 | 1 到 12 |
| 2 | 日 | 1到31 |
| 3 | 小时 | 0到23 |
| 4 | 分钟 | 0到59 |
| 5 | 秒 | 0到61 (60或61 是闰秒) |
| 6 | 一周的第几日 | 0到6 (0是周一) |
| 7 | 一年的第几日 | 1到366 (儒略历) |
| 8 | 夏令时 | -1, 0, 1, -1是决定是否为夏令时的旗帜 |
上述也就是struct_time元组。这种结构具有如下属性:
| 序号 | 属性 | 值 |
|---|---|---|
| 0 | tm_year | 2008 |
| 1 | tm_mon | 1 到 12 |
| 2 | tm_mday | 1 到 31 |
| 3 | tm_hour | 0 到 23 |
| 4 | tm_min | 0 到 59 |
| 5 | tm_sec | 0 到 61 (60或61 是闰秒) |
| 6 | tm_wday | 0到6 (0是周一) |
| 7 | tm_yday | 一年中的第几天,1 到 366 |
| 8 | tm_isdst | 是否为夏令时,值有:1(夏令时)、0(不是夏令时)、-1(未知),默认 -1 |
time
以下时间均为
2020-12-16 15:35:15 周三time.time()
- 获取当前时间戳
1608104115.4493172 - 时间戳单位最适于做日期运算。但是1970年之前的日期就无法以此表示了。太遥远的日期也不行,UNIX和Windows只支持到2038年。
- 获取当前时间戳
time.localtime(时间戳)
获取当前时间
time.struct_time(tm_year=2020, tm_mon=12, tm_mday=16, tm_hour=15, tm_min=35, tm_sec=15, tm_wday=2, tm_yday=351, tm_isdst=0)1
2
3
4
5
6
7
* time.asctime(time.localtime(时间戳))
* 获取格式化的时间
* ```python
Wed Dec 16 15:35:15 2020
time.strftime(format[, time])
格式化日期
# 格式化成2020-12-16 15:35:15形式 print (time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())) # 格式化成Wed Dec 16 15:35:15 2020形式 print (time.strftime("%a %b %d %H:%M:%S %Y", time.localtime())) # 将格式字符串转换为时间戳 a = "Wed Dec 16 15:35:15 2020" print (time.mktime(time.strptime(a,"%a %b %d %H:%M:%S %Y")))1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
**两个非常重要的属性:**
1. time.timezone
* 属性time.timezone是当地时区(未启动夏令时)距离格林威治的偏移秒数(>0,美洲;<=0大部分欧洲,亚洲,非洲)。
2. time.tzname
* 属性time.tzname包含一对根据情况的不同而不同的字符串,分别是带夏令时的本地时区名称,和不带的。
| 序号 | 函数及描述 | 实例 |
| :--- | :----------------------------------------------------------- | :----------------------------------------------------------- |
| 1 | time.altzone<br />返回格林威治西部的夏令时地区的偏移秒数。如果该地区在格林威治东部会返回负值(如西欧,包括英国)。对夏令时启用地区才能使用。 | 以下实例展示了 altzone()函数的使用方法:<br />`>>> import time `<br />`>>> print ("time.altzone %d " % time.altzone) `<br />`time.altzone -28800 ` |
| 2 | time.asctime([tupletime]) <br />接受时间元组并返回一个可读的形式为"Tue Dec 11 18:07:14 2008"(2008年12月11日 周二18时07分14秒)的24个字符的字符串。 | 以下实例展示了 asctime()函数的使用方法:<br />`>>> import time >>> t = time.localtime() `<br />`>>> print ("time.asctime(t): %s " % time.asctime(t)) `<br />`time.asctime(t): Thu Apr 7 10:36:20 2016 ` |
| 3 | [time.clock()](https://www.runoob.com/python3/python3-att-time-clock.html) <br />用以浮点数计算的秒数返回当前的CPU时间。用来衡量不同程序的耗时,比time.time()更有用。 | [实例](https://www.runoob.com/python3/python3-att-time-clock.html)由于该方法依赖操作系统,在 Python 3.3 以后不被推荐,而在 3.8 版本中被移除,需使用下列两个函数替代。`time.perf_counter() # 返回系统运行时间 time.process_time() # 返回进程运行时间` |
| 4 | time.ctime([secs]) <br />作用相当于asctime(localtime(secs)),未给参数相当于asctime() | 以下实例展示了 ctime()函数的使用方法:<br />`>>> import time `<br />`>>> print ("time.ctime() : %s" % time.ctime()) `<br />`time.ctime() : Thu Apr 7 10:51:58 2016` |
| 5 | time.gmtime([secs]) <br />接收时间戳(1970纪元后经过的浮点秒数)并返回格林威治天文时间下的时间元组t。注:t.tm_isdst始终为0 | 以下实例展示了 gmtime()函数的使用方法:<br />`>>> import time `<br />`>>> print ("gmtime :", time.gmtime(1455508609.34375)) `<br />`gmtime: time.struct_time(tm_year=2016, tm_mon=2, tm_mday=15, tm_hour=3, tm_min=56, tm_sec=49, tm_wday=0, tm_yday=46, tm_isdst=0)` |
| 6 | time.localtime([secs] <br />接收时间戳(1970纪元后经过的浮点秒数)并返回当地时间下的时间元组t(t.tm_isdst可取0或1,取决于当地当时是不是夏令时)。 | 以下实例展示了 localtime()函数的使用方法:<br />`>>> import time `<br />`>>> print ("localtime(): ", time.localtime(1455508609.34375)) `<br />`localtime(): time.struct_time(tm_year=2016, tm_mon=2, tm_mday=15, tm_hour=11, tm_min=56, tm_sec=49, tm_wday=0, tm_yday=46, tm_isdst=0)` |
| 7 | [time.mktime(tupletime)](https://www.runoob.com/python3/python3-att-time-mktime.html)<br /> 接受时间元组并返回时间戳(1970纪元后经过的浮点秒数)。 | [实例](https://www.runoob.com/python3/python3-att-time-mktime.html) |
| 8 | time.sleep(secs) <br />推迟调用线程的运行,secs指秒数。 | 以下实例展示了 sleep()函数的使用方法:`#!/usr/bin/python3 import time print ("Start : %s" % time.ctime()) time.sleep( 5 ) print ("End : %s" % time.ctime())` |
| 9 | time.strftime(fmt[,tupletime]) <br />接收以时间元组,并返回以可读字符串表示的当地时间,格式由fmt决定。 | 以下实例展示了 strftime()函数的使用方法:`>>> import time >>> print (time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())) 2016-04-07 11:18:05` |
| 10 | time.strptime(str,fmt='%a %b %d %H:%M:%S %Y') <br />根据fmt的格式把一个时间字符串解析为时间元组。 | 以下实例展示了 strptime()函数的使用方法:`>>> import time >>> struct_time = time.strptime("30 Nov 00", "%d %b %y") >>> print ("返回元组: ", struct_time) 返回元组: time.struct_time(tm_year=2000, tm_mon=11, tm_mday=30, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=335, tm_isdst=-1)` |
| 11 | time.time( ) <br />返回当前时间的时间戳(1970纪元后经过的浮点秒数)。 | 以下实例展示了 time()函数的使用方法:`>>> import time >>> print(time.time()) 1459999336.1963577` |
| 12 | [time.tzset()](https://www.runoob.com/python3/python3-att-time-tzset.html) <br />根据环境变量TZ重新初始化时间相关设置。 | [实例](https://www.runoob.com/python3/python3-att-time-tzset.html) |
| 13 | **time.perf_counter()** <br />返回计时器的精准时间(系统的运行时间),包含整个系统的睡眠时间。由于返回值的基准点是未定义的,所以,只有连续调用的结果之间的差才是有效的。 | [实例](https://www.runoob.com/python3/python3-date-time.html#comment-35499) |
| 14 | **time.process_time()** <br />返回当前进程执行 CPU 的时间总和,不包含睡眠时间。由于返回值的基准点是未定义的,所以,只有连续调用的结果之间的差才是有效的。 | |
**日期格式化符号:**
- %y 两位数的年份表示(00-99)
- %Y 四位数的年份表示(000-9999)
- %m 月份(01-12)
- %d 月内中的一天(0-31)
- %H 24小时制小时数(0-23)
- %I 12小时制小时数(01-12)
- %M 分钟数(00=59)
- %S 秒(00-59)
- %a 本地简化星期名称
- %A 本地完整星期名称
- %b 本地简化的月份名称
- %B 本地完整的月份名称
- %c 本地相应的日期表示和时间表示
- %j 年内的一天(001-366)
- %p 本地A.M.或P.M.的等价符
- %U 一年中的星期数(00-53)星期天为星期的开始
- %w 星期(0-6),星期天为星期的开始
- %W 一年中的星期数(00-53)星期一为星期的开始
- %x 本地相应的日期表示
- %X 本地相应的时间表示
- %Z 当前时区的名称
- %% %号本身
###### calendar
* 星期一是默认的每周第一天,星期天是默认的最后一天。更改设置需调用calendar.setfirstweekday()函数
| 序号 | 函数及描述 |
| :--- | :----------------------------------------------------------- |
| 1 | **calendar.calendar(year,w=2,l=1,c=6)**<br /> 返回一个多行字符串格式的year年年历,3个月一行,间隔距离为c。 每日宽度间隔为w字符。每行长度为21* W+18+2* C。l是每星期行数。 |
| 2 | **calendar.firstweekday( )** <br />返回当前每周起始日期的设置。默认情况下,首次载入caendar模块时返回0,即星期一。 |
| 3 | **calendar.isleap(year)** <br />是闰年返回 True,否则为 false。<br /><img src="python/截屏2020-12-16 下午3.44.04.png" alt="截屏2020-12-16 下午3.44.04" style="zoom:40%;" /> |
| 4 | **calendar.leapdays(y1,y2)** <br />返回在Y1,Y2两年之间的闰年总数。 |
| 5 | **calendar.month(year,month,w=2,l=1)**<br /> 返回一个多行字符串格式的year年month月日历,两行标题,一周一行。每日宽度间隔为w字符。每行的长度为7* w+6。l是每星期的行数。 |
| 6 | **calendar.monthcalendar(year,month)** <br />返回一个整数的单层嵌套列表。每个子列表装载代表一个星期的整数。Year年month月外的日期都设为0;范围内的日子都由该月第几日表示,从1开始。 |
| 7 | **calendar.monthrange(year,month)** <br />返回两个整数。第一个是该月的星期几,第二个是该月有几天。星期几是从0(星期一)到 6(星期日)。<br /><img src="python/截屏2020-12-16 下午3.44.50.png" alt="截屏2020-12-16 下午3.44.50" style="zoom:45%;" /><br />(5, 30)解释:5 表示 2014 年 11 月份的第一天是周六,30 表示 2014 年 11 月份总共有 30 天。 |
| 8 | **calendar.prcal(year, w=0, l=0, c=6, m=3)** <br />相当于 print (calendar.calendar(year, w=0, l=0, c=6, m=3))。 |
| 9 | **calendar.prmonth(theyear, themonth, w=0, l=0)** <br />相当于 **print(calendar.month(theyear, themonth, w=0, l=0))**。 |
| 10 | **calendar.setfirstweekday(weekday)** <br />设置每周的起始日期码。0(星期一)到6(星期日)。 |
| 11 | **calendar.timegm(tupletime)** <br />和time.gmtime相反:接受一个时间元组形式,返回该时刻的时间戳(1970纪元后经过的浮点秒数)。 |
| 12 | **calendar.weekday(year,month,day)**<br /> 返回给定日期的日期码。0(星期一)到6(星期日)。月份为 1(一月) 到 12(12月)。 |
###### datetime
- [datetime模块](https://docs.python.org/3/library/datetime.html)
- datetime模块为日期和时间处理同时提供了简单和复杂的方法。
- 支持日期和时间算法的同时,实现的重点放在更有效的处理和格式化输出。
- 该模块还支持时区处理
```python
now = date.today()
print(str(now)) # 2020-12-17
print(now.strftime("%m-%d-%y. %d %b %Y is a %A on the %d day of %B."))
# 212-17-20. 17 Dec 2020 is a Thursday on the 17 day of December.
birthday = date(1964, 7, 31)
age = now - birthday
print(birthday) # 1964-07-31
print(age) # 20593 days, 0:00:00
print(age.days) # 20593
内置函数(build.in)
排序
1 | list.sort(key=lambda x: x[1], reverse=True) |
- 根据value(x[1])值来进行排序
- dict是无序的,所以即使sorted了,得到的依然不是完全的排序号的
面向对象
- 类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
- 方法:类中定义的函数。
- 类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
- 数据成员:类变量或者实例变量用于处理类及其实例对象的相关的数据。
- 方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
- 局部变量:定义在方法中的变量,只作用于当前实例的类。
- 实例变量:在类的声明中,属性是用变量来表示的,这种变量就称为实例变量,实例变量就是一个用 self 修饰的变量。
- 继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟”是一个(is-a)”关系(例图,Dog是一个Animal)。
- 实例化:创建一个类的实例,类的具体对象。
- 对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
类
1 | class MyClass: |
- 在类的内部,使用
def关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数self,且为第一个参数self代表的是类的实例,代表当前对象的地址,而self.class则指向类。self的名字并不是规定死的,也可以使用this,但是最好还是按照约定是用self。
- 类方法必须包含参数
self, 且为第一个参数
- 类方法必须包含参数
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时self.__private_attrs。__private_method:两个下划线开头,声明该方法为私有方法,只能在类的内部调用 ,不能在类的外部调用。self.__private_methods。
类的专有方法:
- __init__ : 构造函数,在生成对象时调用
- __del__ : 析构函数,释放对象时使用
- __repr__ : 打印,转换
- __setitem__ : 按照索引赋值
- __getitem__: 按照索引获取值
- __len__: 获得长度
- __cmp__: 比较运算
- __call__: 函数调用
- __add__: 加运算
- __sub__: 减运算
- __mul__: 乘运算
- __truediv__: 除运算
- __mod__: 求余运算
- __pow__: 乘方
运算符重载:
1 | class Vector: |
继承
1 | class DerivedClassName(BaseClassName1, BaseClassNameN): |
单继承
- 以下实例
student继承people
1 | #类定义 |
多继承
- 需要注意圆括号中父类的顺序,若是父类中有相同的方法名,而在子类使用时未指定,python从左至右搜索,即方法在子类中未找到时,从左到右查找父类中是否包含方法。
1 | #类定义 |
方法重写
1 | class Parent: # 定义父类 |
- super() 函数:用于调用父类(超类)的一个方法。
接口
1 | class Super: |
打包
pyinstaller
- 打包py文件,将在当前目录生成一个
.spec文件和dist目录,可执行文件在dist目录下
1 | pip install pyinstaller |
=======
- 终端切换
1 | chsh -s /bin/zsh |
一些错误

- 字典类型的键是不可变的,可以使用数字、字符串或元组充当,但是不能使用列表作为键值
- Post title:python
- Post author:Wei Jieyang
- Create time:2020-12-15 14:32:10
- Post link:https://jieyang-wei.github.io/2020/12/15/python/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.